ChatDiT is a zero-shot, general-purpose, and interative visual generation framework built directly upon pretrained diffusion transformers (DiTs) with no additional tuning, adapters, or modifications.
With its intuitive interface, ChatDiT enables seamless multi-round, free-form conversations with DiTs. It supports referencing zero to multiple images to generate a new set of images, or, if desired, a fully illustrated article in response.
Abstract
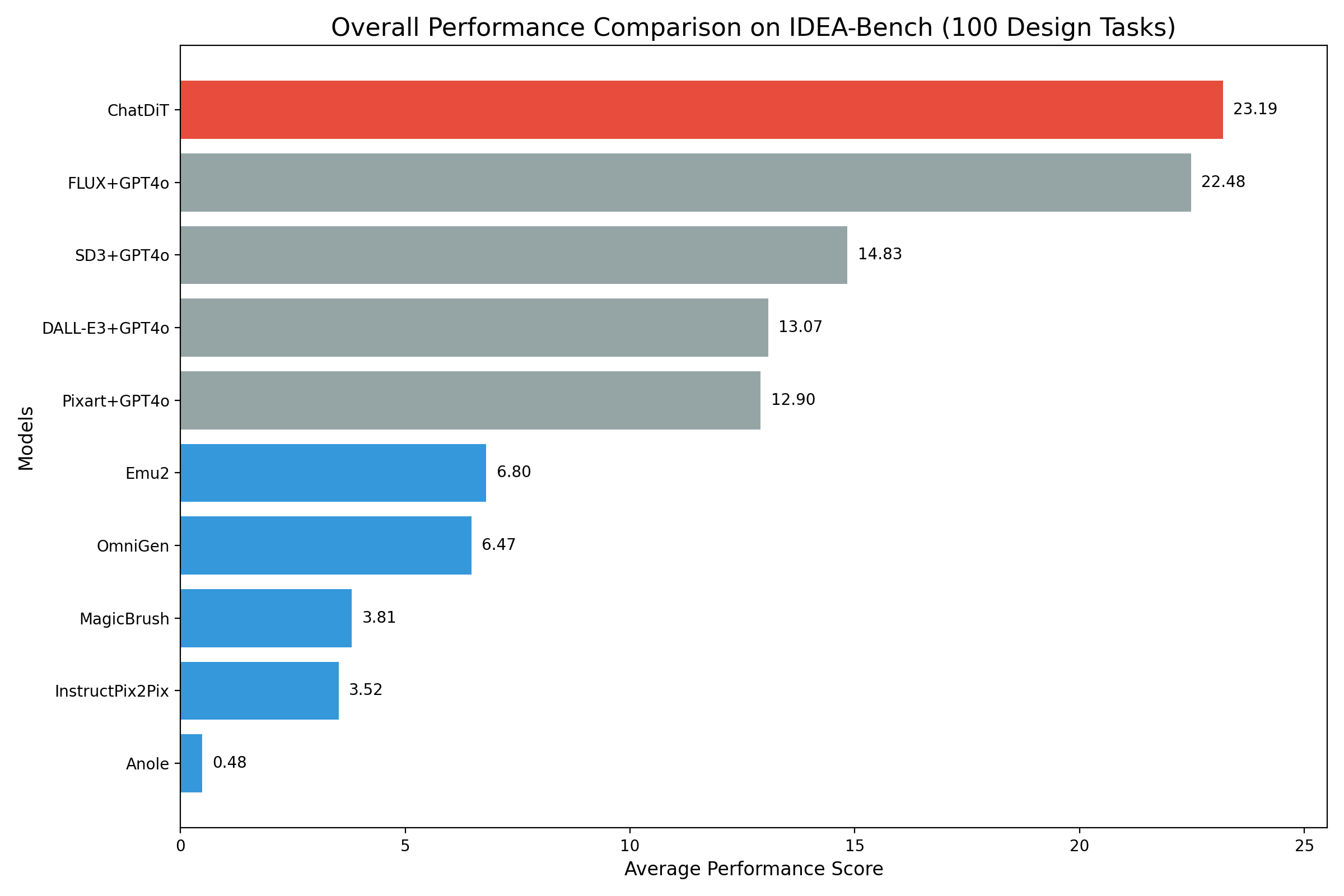
Recent research [Huang et al., 2024a,b] has highlighted the inherent in-context generation capabilities of pretrained diffusion transformers (DiTs), enabling them to seamlessly adapt to diverse visual tasks with minimal or no architectural modifications. These capabilities are unlocked by concatenating self-attention tokens across multiple input and target images, combined with grouped and masked generation pipelines. Building upon this foundation, we present ChatDiT, a zero-shot, general-purpose, and interactive visual generation framework that leverages pretrained diffusion transformers in their original form, requiring no additional tuning, adapters, or modifications. Users can interact with ChatDiT to create interleaved text-image articles, multi-page picture books, edit images, design IP derivatives, or develop character design settings, all through free-form natural language across one or more conversational rounds. At its core, ChatDiT employs a multi-agent system comprising three key components: an Instruction-Parsing agent that interprets user-uploaded images and instructions, a Strategy-Planning agent that devises single-step or multi-step generation actions, and an Execution agent that performs these actions using an in-context toolkit of diffusion transformers. We thoroughly evaluate ChatDiT on a benchmark of 100 real-world design tasks, spanning 275 cases with diverse instructions and varying numbers of input and target images. Despite its simplicity and training-free approach, ChatDiT surpasses all competitors, including those specifically designed and trained on extensive multi-task datasets. While this work highlights the untapped potential of pretrained text-to-image models for zero-shot task generalization, we also note that ChatDiT's Top-1 performance on IDEA-Bench achieves a score of 23.19 out of 100, reflecting challenges in fully exploiting DiTs for general-purpose generation. We further identify key limitations of pretrained DiTs in adapting to certain tasks. We release all code, agents, results, and intermediate outputs to facilitate further research at here.
Single-Round Chat
ChatDiT allows users to provide natural language instructions along with zero or more uploaded images as input. Based on these inputs, it automatically generates a set of images, determining both the number and content of the outputs dynamically. The examples below showcase ChatDiT's selected results on IDEA-Bench. The user messages here are condensed summaries of the original detailed instructions to conserve space.
Multi-Round Chat
ChatDiT allows users to provide natural language instructions along with zero or more uploaded images as input. Based on these inputs, it automatically generates a set of images, determining both the number and content of the outputs dynamically. The examples below showcase ChatDiT's selected results on IDEA-Bench. The user messages here are condensed summaries of the original detailed instructions to conserve space.
Illustrated Article Generation
ChatDiT allows users to provide natural language instructions along with zero or more uploaded images as input. Based on these inputs, it automatically generates a set of images, determining both the number and content of the outputs dynamically. The examples below showcase ChatDiT's selected results on IDEA-Bench. The user messages here are condensed summaries of the original detailed instructions to conserve space.
Comparison with Existing Approaches
A comparison of selected cases of ChatDiT with top-performing approaches on IDEA-Bench, using varied instructions and input-output settings. For further analysis and details, please refer to our paper.
Overview of the ChatDiT multi-agent framework. The framework consists of three core agents operating sequentially: the Instruction-Parsing Agent interprets user instructions and analyzes inputs, the Strategy-Planning Agent formulates in-context generation strategies, and the Execution Agent performs the planned actions using the in-context toolkit of pretrained diffusion transformers. An optional Markdown Agent integrates the outputs into cohesive, illustrated articles. Sub-agents handle specialized tasks within each core agent, ensuring flexibility and precision in generation. For more implementation details, please refer to our paper.
BibTex
@article{lhhuang2024chatdit,
title={ChatDiT: A Training-Free Baseline for Task-Agnostic Free-Form Chatting with Diffusion Transformers},
author={Huang, Lianghua and Wang, Wei and Wu, Zhi-Fan and Shi, Yupeng and Liang, Chen and Shen, Tong and Zhang, Han and Dou, Huanzhang and Liu, Yu and Zhou, Jingren},
booktitle={arXiv preprint arxiv:2412.12571},
year={2024}
}